Describing Handwriting, Part IV: Recapitulation and Formal Model
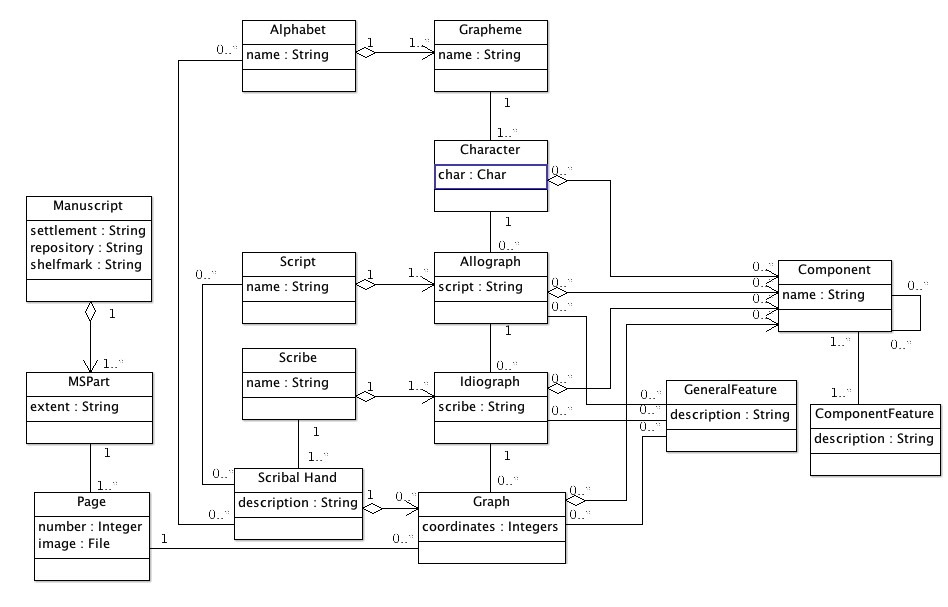
In the previous post, I promised to give more concrete examples of how this system might work in practice. Before doing so, however, I first want to recap a bit and try to formalise the discussion so far. I was brought up with UML, Unified Modelling Language, which is a formal way of expressing entities and relationships in a way that a computer can understand. This is very technical and not at all easy to understand unless you're already familiar with it, but I give it now partly as a way of documenting what we are doing and also for those of you who are already familiar with the system. The diagram here doesn't follow the rules of UML to the letter but should at least be close enough to capture the idea.
My first version of a UML Class Diagram for the conceptual model so far is as follows:

[Edit, 17 October 2011: The UML diagram has been altered from the original by associating Script, Scribe and Hand directly with Component as a way of capturing elements of style which are common across multiple characters.]
{kind=link}
What does this mean?
- Starting at the top, it states that a GRAPHEME is associated with one or more CHARACTERS (for 'Character' see below). A CHARACTER is made up of any number of COMPONENTS. A COMPONENT in turn can be found in any number of CHARACTERS and can have one or more FEATURES or indeed any number of further COMPONENTS.
- A CHARACTER can also be manifested in one or more ALLOGRAPHS, and a set of ALLOGRAPHS makes up a SCRIPT. ALLOGRAPHS themselves can have COMPONENTS which have FEATURES, but ALLOGRAPHS also have GENERALFEATURES which are the aspects of 'style' discussed in Part III. A set of ALLOGRAPHS together makes up a SCRIPT.
- Each ALLOGRAPH can be manifested in any number of IDIOGRAPHS (which in turn have COMPONENTS and GENERAL FEATURES). A set of IDIOGRAPHS makes up the practice of a SCRIBE.
- Each IDIOGRAPH can appear on the PAGE as a GRAPH; GRAPHS have the usual set of GENERAL FEATURES and COMPONENTS, as well as a set of coordinates. The set of GRAPHS makes up a SCRIBAL HAND.
- SCRIBAL HANDS are written by exactly one SCRIBE (but a SCRIBE can write many SCRIBAL HANDS); a SCRIBAL HAND may also be written in one or more SCRIPTS and may use one or more ALPHABETS.
Conceptual Questions
This discussion raises some conceptual questions that I can see:
- Is GRAPH - IDIOGRAPH - ALLOGRAPH - CHARACTER - GRAPHEME a simple association or one of specialisation? I can see arguments for both.
- Is SCRIBE the correct term here? Strictly the SCRIBE is a person, whereas the set of IDIOGRAPHS make up a scribal practice.
- Based on the discussion of Style in Part III, shouldn't there be relationships from SCRIBE and SCRIBAL HAND directly to GENERAL STYLE (or some other entity)?
- Are the cardinalities correct? Can a CHARACTER really have no COMPONENTS? I think so, at least in the abstract -- what are the components of a punctus, for example? Or should 'dot' be considered a COMPONENT, in which case even a punctus is covered?
- The relationship names are not in place, partly because I'm not entirely confident about the terminology I used previously. In what sense is an allograph related to an idiograph? Do we have a terminology for this? It feels to me very analogous to Group 1 entities in FRBR but I'm not convinced that the terms apply directly.
Terminology (again): When is a Grapheme not a Grapheme? When it's a Character?
I have also come to appreciate that graphemes refer only to the abstract and do not in themselves have a physical manifestation; they are therefore not relevant to palaeography and so we need another term. A useful source here is the Glossary of Unicode Terms and Section 4 in Chapter 3 of the Unicode Standard, since they have been dealing with these concepts for a long time and in a way that requires much more precision than palaeographers need. For instance, a grapheme properly has no physical form and so cannot be described or even considered in a palaeographical context; here Unicode's Character or perhaps Abstract Character seems more correct. Note that, according to Sense (1) in the Unicode standard, 'character' is '[t]he smallest component of written language that has semantic value': it follows, therefore, that 'A' and 'a' are instances of the same character. Note, however, that this is not the usual definition in computer science and doesn't even seem to be the definition usually applied to Unicode which seems more like Sense (3), 'The basic unit of encoding for the Unicode character encoding' (sic). Presumably this is the sense meant when 'LATIN CAPITAL A' is described as a different character to 'LATIN SMALL LETTER A'. This definition does seem to work here, since in palaeography we must distinguish between minuscule and majuscule forms. Unicode's 'Letter' is not strictly appropriate, (a) because it excludes punctuation and other symbols such as the Tironian nota, and (b) because it's not clear to me, at least, if it can include a visual form (what exactly is the 'informative property' of a character?). I therefore stick with 'character' for the time being, but am very open to suggestions. In the next post, I will continue towards a concrete example, starting with lists of all the characters, components, features and some allographs of English Vernacular minuscule.
Share on Twitter Share on Facebook
Comments